ギャンブラー問題(強化学習第2版 4.4 価値反復)
# ギャンブラー問題
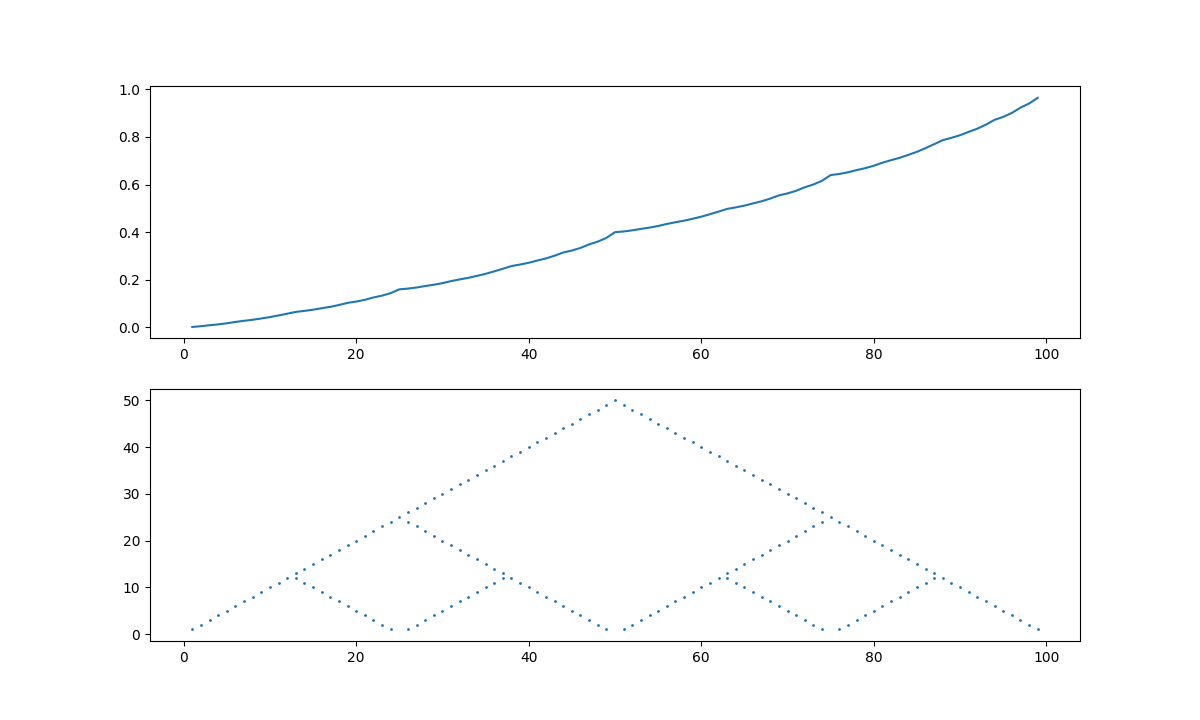
$p_h=0.4,0.25,0.55$それぞれのギャンブラー問題について、価値反復を用いて最適方策を求めた。
実装は、 reinforcement_learning/main.cpp at main - niuez/reinforcement_learningに載せてある。
価値関数と、最適方策を図にした。
# $p_h=0.4$
# $p_h=0.25$

$p_h \leq 0.5$では、どこかで賭けをして勝ちを狙いに行く必要があるっぽい。
# $p_h=0.55$
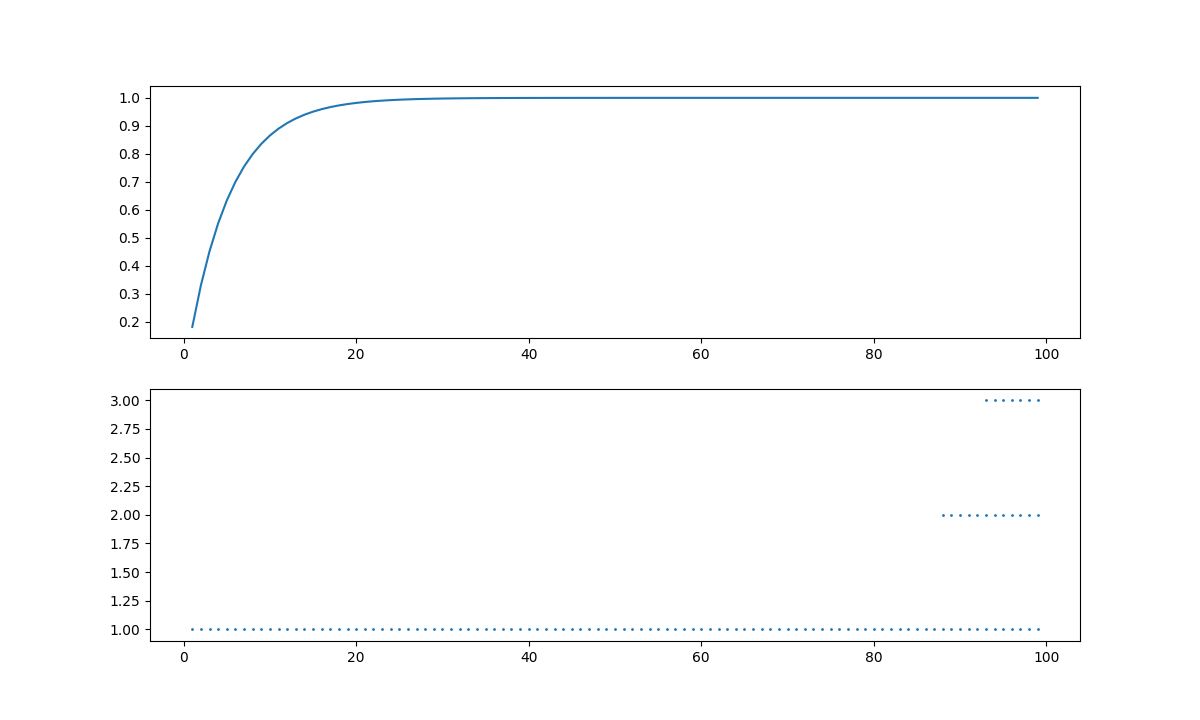
$p_h=0.55$については、少しずつ掛けて勝つことができるのでこのような結果になった。